
François Chollet’s ARC-AGI-3 Is Here, and It’s a Brutal Reality Check for “Agentic” AI
François Chollet’s ARC-AGI-3 Is Here, and It’s a Brutal Reality Check for “Agentic” AI
March 31, 2026
François Chollet and the ARC Prize team have released ARC-AGI-3, a new benchmark that swaps static puzzles for interactive environments, and the timing could not be sharper. Right now, every AI vendor wants you to believe their model is one workflow away from becoming your tireless digital coworker. ARC-AGI-3 walks into that party, turns on the lights, and asks a much less flattering question: can today’s systems actually adapt when the rules are new, the goal is unclear, and there is no prompt-shaped handrail?
The short version: humans can. Frontier AI systems mostly cannot. And for anyone building marketing automation, creative pipelines, or executive AI workflows, that gap matters more than another leaderboard screenshot with a confetti emoji attached.
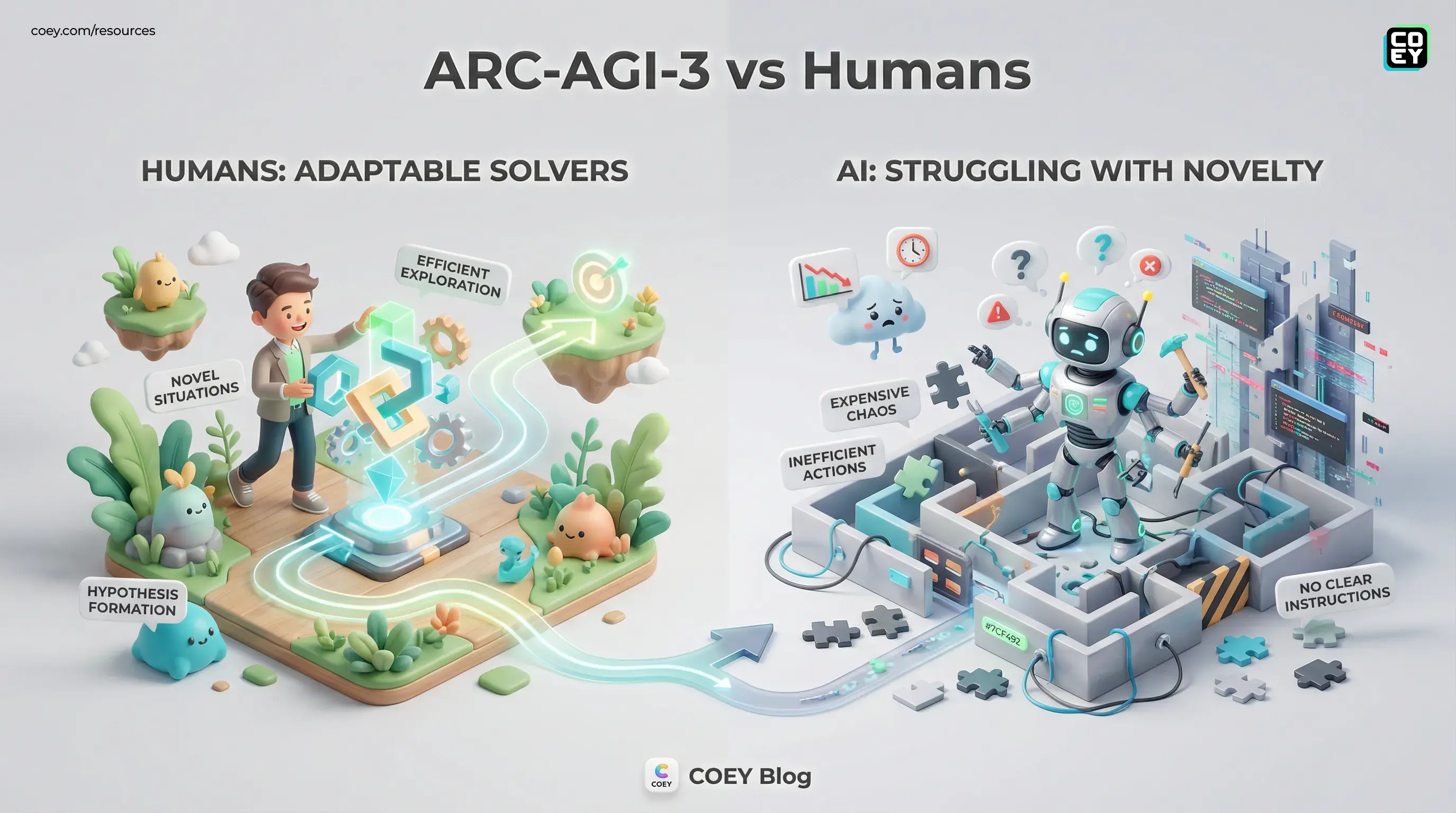
ARC-AGI-3 is not testing whether a model has seen enough of the internet. It is testing whether a system can enter a novel situation, explore intelligently, form hypotheses, and adjust without collapsing into expensive chaos.
What ARC-AGI-3 actually is
ARC-AGI began as Chollet’s attempt to measure generalization rather than memorization. Earlier versions used static tasks. ARC-AGI-3 changes the format dramatically: instead of one-shot puzzle solving, the benchmark drops an AI system into interactive environments with no explicit instructions, no stated goals, and no domain hints.
Think less “answer this prompt” and more “figure out this weird little game world from scratch.” The agent has to act, observe outcomes, infer the hidden rules, and reach the objective efficiently. That is a much closer match for real-world automation than a benchmark that rewards polished text output on familiar formats.
According to the ARC Prize materials and the public paper on arXiv, humans are used as the feasibility baseline. The environments are designed to be solvable by ordinary people without special training. The score is not just whether a task gets solved, but how efficiently it gets solved relative to human performance.
Why that scoring model matters
This benchmark punishes flailing. If a human can solve a task in a handful of actions and a model needs dozens, hundreds, or never gets there at all, that matters. In workflow terms, those extra steps translate into:
- more retries
- more tool calls
- more compute spend
- more human intervention
- more opportunities for the system to quietly do something dumb
That is not a benchmark detail. That is your operations budget.
Why this matters beyond research
It is tempting to file ARC-AGI-3 under “interesting academic benchmark, moving on.” That would be a mistake. This release matters because it targets the exact category of failure that shows up when businesses try to move from AI demos to AI systems.
Most models look capable when the task is familiar, the instructions are explicit, and the format is narrow. But production work is messier. Briefs change. Inputs arrive malformed. New channels appear. A client asks for something no one templated. A tool returns a weird result. The campaign data contradicts the creative narrative. Suddenly the “smart” system needs to adapt, not just autocomplete.
ARC-AGI-3 is designed to expose whether that adaptation is real or just benchmark cosplay.
| What ARC-AGI-3 tests | Workflow translation | Why teams should care |
|---|---|---|
| Novel interactive tasks | Handling unfamiliar situations | Shows whether automation survives edge cases |
| Efficiency-based scoring | Steps, retries, wasted actions | Maps to cost, latency, and babysitting |
| No explicit instructions | Goal inference and exploration | Tests whether systems can adapt without hand-holding |
Frontier models are still struggling
The early numbers are the headline, and they are not flattering. Public launch materials and reporting around ARC-AGI-3 indicate that leading frontier systems score well below 1% on the benchmark’s efficiency metric, while humans remain the practical reference point for solvability.
Public reporting around the launch has cited results such as Gemini 3.1 Pro at about 0.37%, GPT-5.4 at about 0.26%, and Claude Opus 4.6 at about 0.25%, with other major models similarly clustered near the floor. Even allowing for harness differences and inevitable benchmark debates, the directional message is clear enough: current systems still struggle badly when real adaptation is required.
That does not mean today’s LLMs are useless. It means they are often being used outside their actual comfort zone. They are strong at pattern completion, structured generation, summarization, and increasingly solid tool use when the lane markings are clear. They are much weaker at entering a truly novel environment and figuring it out with human-like efficiency.
In plain English: your AI assistant may look slick in a controlled workflow, then immediately become a confused intern the second the environment stops resembling its training distribution.
Can you automate ARC-AGI-3 itself?
Yes, and this is where the release becomes operationally useful rather than just philosophically spicy. ARC-AGI-3 is published openly through the ARC Prize ecosystem, including the benchmark page and accompanying research materials.
For non-technical teams, here is the practical translation: this is not trapped in a shiny website demo. If your team evaluates models internally, you can use ARC-AGI-3 in repeatable testing pipelines to compare systems, measure regressions, and pressure-test claims around “agents” and “general reasoning.”
What API and integration readiness mean here
ARC-AGI-3 is not a marketing product with a plug-and-play SaaS onboarding flow, and it is not meant to be. But it does ship with benchmark tooling and documentation that can be run programmatically. That gives it real value for:
- AI product teams evaluating model upgrades
- enterprise teams comparing vendor claims
- agencies building multi-model routing layers
- research groups testing exploration and planning architectures
| Question | Best answer | Practical meaning |
|---|---|---|
| Can it be automated? | Yes | Useful for recurring evals and regression tests |
| Is it API-friendly? | Yes, as benchmark infrastructure | Can plug into internal model testing workflows |
| Is it end-user software? | No | This is for measuring systems, not running campaigns |
What marketers and execs should do with this
If you lead a marketing team, creative operation, or AI procurement process, ARC-AGI-3 is not telling you to stop using AI. It is telling you to stop confusing good UI output with robust system behavior.
That distinction matters because the next phase of enterprise AI is not about who has the prettiest chat window. It is about who can reliably plug models into workflows without turning every edge case into an escalation thread.
For creators and operators, the practical takeaways are straightforward:
Benchmarks should inform procurement
If a vendor is selling “agentic automation,” you should care whether their system can adapt under uncertainty, not just whether it writes nice copy. ARC-AGI-3 offers a better lens for that than traditional static benchmarks.
Use the right model for the right job
Most automation does not need general intelligence. It needs bounded competence. Use cheaper, faster models for repeatable generation. Use stronger systems for decision nodes. Keep humans on novel, high-stakes, ambiguous work. That division of labor is still the grown-up strategy.
Keep humans in the loop where novelty appears
ARC-AGI-3 is basically a flashing neon sign that says: novelty is still where humans dominate. When the job requires taste, hypothesis formation, or navigating unclear objectives, human plus machine is still the winning architecture.
If you want a related read on how COEY has been thinking about automation-focused evaluation and workflow design, our coverage of portable AI workflow design is a strong companion to this benchmark story.
The bigger signal for AI workflows
ARC-AGI-3 lands at a useful moment because the market is full of inflated expectations around agents. Every week, a new product promises autonomous workflow magic. Some of that is real. Some of it is just prompt chaining in a trench coat.
This benchmark does not end that conversation, but it does sharpen it. It suggests that real progress toward adaptable, general-purpose AI systems will require more than scaling the same recipe. Better exploration, better planning, better environment modeling, and probably new architectures all look increasingly necessary.
That is healthy news, honestly. It keeps the industry honest. It pushes teams to test instead of vibe. And it reinforces a point we care about deeply: AI scales creativity best when it collaborates with humans, not when it pretends to replace them.
ARC-AGI-3 matters because it measures the thing that production teams eventually discover the hard way: generating impressive output is not the same as adapting intelligently. If you are building automations, buying AI systems, or trying to scale creative work without scaling chaos, that difference is the whole game.



