
NVIDIA has released Nemotron-OCR-v2 on Hugging Face, and this is the kind of launch that matters less because “AI did another benchmark thing” and more because it targets a brutally boring business problem that still eats real time: getting messy documents into systems that can actually use them.
Nemotron-OCR-v2 is an open-weights OCR system built for multilingual text extraction, layout understanding, and reading-order reconstruction across documents and real-world images. In plain English, it is trying to do more than rip text off a page. It is trying to preserve enough structure that forms, tables, scanned PDFs, screenshots, and multi-column documents stop acting like little sabotage devices inside your workflow.
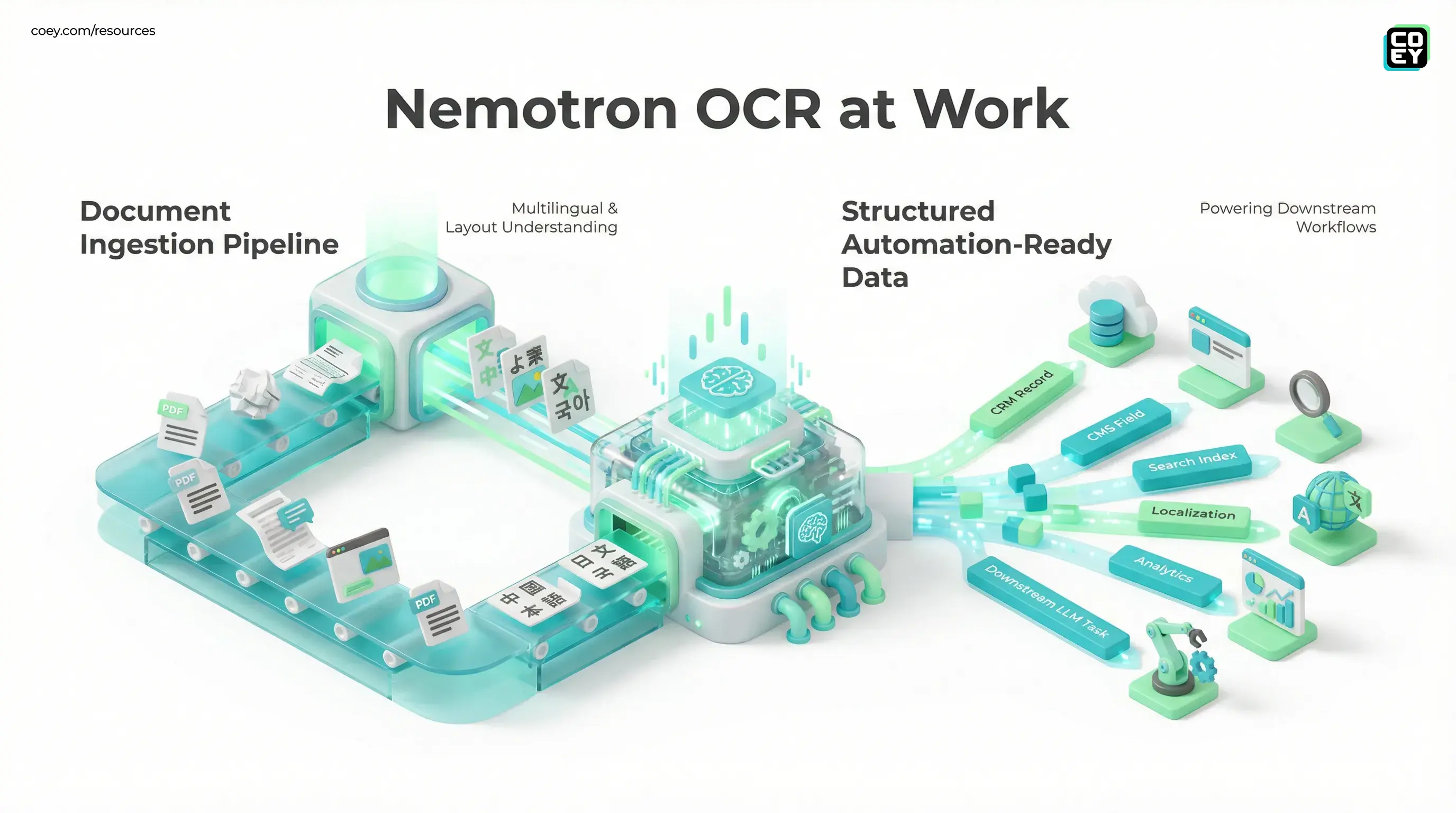
The important shift: this is not “OCR, but shinier.” It is OCR that is much closer to becoming an automation layer.
For executives and operators, that distinction matters. If your team still has people manually rekeying PDFs, dragging copy out of scans, rebuilding tables, or cleaning up layout damage before work can even begin, Nemotron-OCR-v2 points at a more scalable model: humans handle judgment and exceptions, machines handle the extraction grind.
What NVIDIA actually shipped
According to the model card, Nemotron-OCR-v2 is a multilingual OCR stack composed of a text detector, a recognizer, and a relational model that helps infer layout and reading order. NVIDIA provides two variants: an English-focused model optimized around word-level regions, and a multilingual version that supports English, Simplified Chinese, Traditional Chinese, Japanese, Korean, and Russian with line-level document handling.
That architecture matters because a lot of legacy OCR still behaves like a raccoon dumped into a filing cabinet: it grabs text fragments, drops half the context, and leaves you to figure out what belonged where. Nemotron-OCR-v2 is built to understand not just characters, but the spatial relationships between them.
What stands out
- Open weights: teams can download and deploy it instead of being forced into one closed SaaS lane.
- Structured extraction posture: better suited to preserving document logic, not just plain text strings.
- Multilingual coverage: useful for global teams dealing with mixed-language assets and client submissions.
- Layout awareness: stronger fit for tables, forms, reading order, and messy real-world formatting.
| Capability | What it means | Why teams care |
|---|---|---|
| Open weights | Self-hosting is possible | More control, privacy, and less vendor lock-in |
| Layout understanding | Preserves structure and reading order | Better for downstream automation than flat text dumps |
| Multilingual support | Handles six named languages in the multilingual variant | Useful for global document pipelines |
Why this matters beyond OCR
Most businesses do not have a “document problem.” They have a workflow bottleneck disguised as a document problem. The issue is rarely the PDF itself. The issue is that the PDF cannot talk to anything useful without a human translating it first.
That is why Nemotron-OCR-v2 is more interesting than a standard OCR upgrade. If the output is good enough to preserve structure and context, the extracted data can move into CRM records, CMS fields, localization systems, compliance checks, analytics pipelines, archive indexing, or downstream LLM tasks with less cleanup in the middle.
That is where COEY’s broader thesis shows up: scale happens when machines handle the repetitive conversion work and humans stay focused on intent, QA, and decision-making. Not glamorous. Extremely profitable.
For marketers, yes, this is your problem too
It is easy to hear “OCR” and assume this is someone else’s headache in finance or legal. Cute. But marketing teams deal with document sludge constantly:
- client briefs trapped in PDFs and scans
- legacy brochures and sales collateral that need reuse
- regional assets and forms that need localization
- creative approvals and screenshots that must be archived or audited
- tables and spec sheets that have to become web-ready content
If your content ops still begin with “someone has to manually pull all this out first,” then OCR quality directly affects creative velocity. Better extraction means faster ingestion. Faster ingestion means faster production. And faster production, when paired with human review, is how teams scale without turning every launch into admin cosplay.
Can you automate it?
Yes, more realistically than many model launches.
This is where Nemotron-OCR-v2 gets especially practical. Because it is released as open weights rather than locked behind a single product UI, teams can deploy it inside their own infrastructure and wrap it with the API surface they need. That means it can become part of a repeatable system instead of a manual side quest.
For non-technical readers, here is the plain-English translation:
- Can it plug into your stack? Yes, if your team can run models or use a service wrapper around them.
- Can it be triggered automatically? Yes, from uploads, queues, forms, inboxes, or storage events.
- Is it trapped in a closed app? No, and that is the big deal.
In practice, teams could expose Nemotron-OCR-v2 through an internal REST endpoint, route documents into it from orchestration tools, and send structured outputs downstream to review or storage systems. If you are already working with automation platforms, this is the kind of model that fits nicely into an ingestion-first workflow.
That also aligns with the bigger pattern we have covered at COEY around structured outputs as the real automation primitive. OCR matters most when the result behaves like machine-readable input, not just text you can stare at in a browser.
How ready is it for real work?
Promising, with the usual adult caveats.
Nemotron-OCR-v2 looks materially more workflow-ready than old-school OCR that falls apart the moment a page has columns, mixed scripts, odd spacing, or a table that did not ask permission before existing. NVIDIA says the model was trained on about 12 million images, including roughly 680,000 real-world samples and about 11 million synthetic ones, and benchmarked on document-heavy tasks including multilingual and structurally complex settings.
That said, this is not “throw every terrible fax from 2009 at it and achieve enlightenment.” Real-world readiness still depends on your documents, your QA rules, and how much cleanup your downstream systems can tolerate.
What looks ready now
- Document ingestion pipelines for scanned PDFs, forms, screenshots, and archives
- Localization prep where text and layout both matter
- Search and indexing across historical business documents
- Structured extraction workflows feeding other AI or rules-based systems
What still needs human review
- Compliance-sensitive extraction where missing a field creates risk
- Messy edge cases such as poor scans, handwriting, or extreme formatting damage
- Mission-critical tables and audits where “mostly right” is still wrong
| Use case | Readiness | Human role |
|---|---|---|
| Bulk archive extraction | High | Spot-check output quality and edge cases |
| Marketing asset intake | High | Approve mapping into CMS or workflows |
| Regulated document processing | Medium | Validate critical fields before action |
Why open weights change the equation
Open release is not automatically superior to hosted APIs, but in document AI it changes the economics and the governance story in a very real way.
With open weights, teams are not stuck waiting for a vendor to expose the exact feature they need. They can deploy privately, control throughput, manage sensitive inputs internally, and avoid pay-per-document surprises that turn scale into a budgeting horror show. That is especially relevant for organizations handling confidential files, regulated records, or high document volumes.
It also means Nemotron-OCR-v2 can be combined with custom post-processing, validation rules, and routing logic in ways that closed OCR products often make annoying or impossible. If your process needs extra QA, JSON normalization, table-specific parsing, or integration with a private content system, open deployment gives you more room to build the stack you actually need.
For a broader adjacent example of why “callable and deployable” matters more than shiny demos, our recent post on Cohere Transcribe made the same point in audio: the unlock is not just model quality, it is whether the thing can become infrastructure.
Bottom line
Nemotron-OCR-v2 is not exciting because it says OCR in a more NVIDIA-sounding font. It is exciting because it makes document extraction look more like a controllable, automation-ready system component.
The combination of open weights, multilingual support, and stronger layout understanding makes this a meaningful release for any team buried under scanned PDFs, forms, tables, screenshots, and business documents that still require human cleanup before useful work can begin. It is especially relevant for operators and marketers who want to remove low-value manual conversion from the creative process and turn documents into structured inputs machines can actually act on.
That does not mean “fire up autopilot and trust every output blindly.” It means the machine can finally take more of the boring middle. Humans still decide what matters, what is accurate, and what ships. But if Nemotron-OCR-v2 performs well in your environment, it can help collapse one of the oldest friction points in digital work: getting information out of dead documents and into living systems.
Which, frankly, is a much better use of AI than making another chatbot explain your own PDF back to you like it discovered fire.
For marketing leaders ready to turn AI strategy into production workflows, explore the Executive AI Accelerator.



