
Step3 Open-Source VLM Built for Automation
Step3 Open-Source VLM Built for Automation
January 14, 2026
StepFun has open-sourced Step3, a multimodal reasoning model designed to bring serious vision + language capability to teams that do not want their AI strategy to be “buy more cloud credits and cope.” The official release lives on the Step3 research page, with code available on GitHub and model weights published on Hugging Face.
If you have been waiting for a multimodal model that is more “workflow component” than “research flex,” Step3 is at least aiming in the right direction. And yes, there is a pragmatic point here: Step3 is released under Apache 2.0, which is the licensing equivalent of “go build your business, just do not blame us.”

The shift: multimodal AI is moving from “can it describe the image?” to “can it become a callable stage inside operations?” Step3 is explicitly trying to be the latter.
What Step3 actually shipped
Step3 is a multimodal reasoning model (vision + language) built with a Mixture-of-Experts (MoE) architecture. StepFun’s documentation describes the model as having 321B total parameters (VLM), with about 38B active during inference. (StepFun also breaks out the LLM portion separately at 316B total parameters, with the same roughly 38B activated per token.) In practical terms: you are not paying the compute price of all 321B every time you run a request. That is the point of MoE: large “brain,” selective “neurons” firing per token.
Step3 also supports a long context window (StepFun cites up to 65,536 tokens), which matters for real-world multimodal tasks like:
- reviewing long creative briefs plus image sets in one pass
- reading multi-page PDFs with embedded visuals
- doing audit-style QA across many assets without losing thread
Why the architecture matters
StepFun’s repo highlights efficiency-oriented design choices like Multi-Matrix Factorization Attention (MFA) and Attention-FFN Disaggregation (AFD), which are engineering moves to reduce memory and improve throughput. In plain English: this is a model designed to be served, not just admired.
Why this matters for marketing and creative ops
Most teams do not need a model that can “see.” They need a model that can replace tedious human checking loops without replacing human judgment. The value is not the caption. It is the automation.
Where Step3’s multimodal profile gets interesting for marketers and media operators:
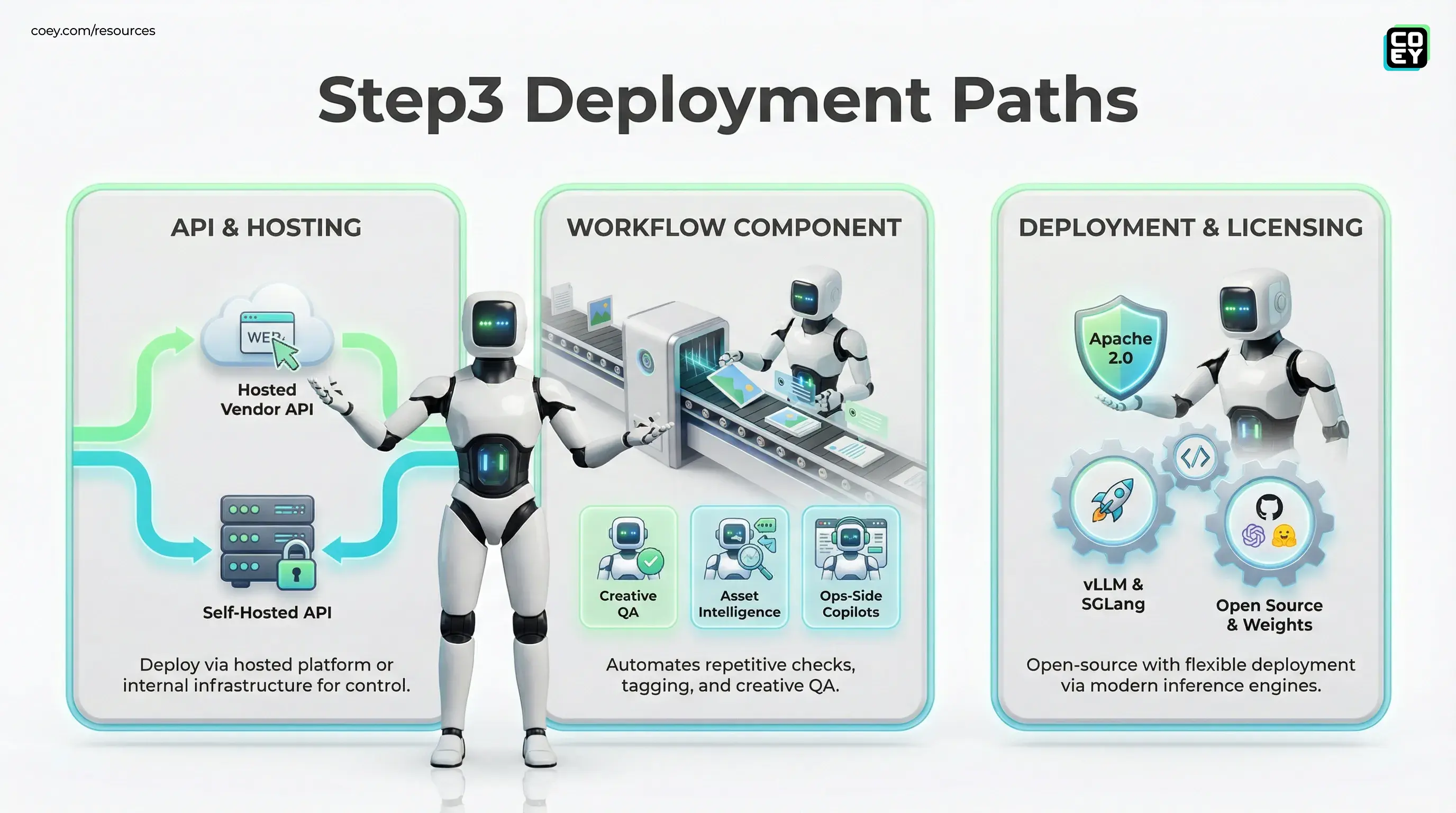
- Creative QA: scan assets for brand rules (logo presence, required disclaimers, layout constraints) before anything goes out.
- Asset intelligence: auto-tag images and screenshots for DAM search and reuse (products, scenes, props, contexts).
- Screenshot-to-action workflows: interpret dashboards, ad manager screenshots, landing page screenshots, and turn them into structured feedback.
- Ops-side copilots: “Look at this slide deck screenshot and tell me what is missing for legal or compliance.”
Reality: Multimodal is only “useful” when it reduces the number of times your team has to manually eyeball the same asset categories every week.
Automation potential: can you plug it in?
This is the part that separates “cool model drop” from “workflow-ready.” Step3 is open-source and open-weight, which means you can deploy it inside your own infrastructure, wrap it behind a service endpoint, and call it from anything that speaks HTTP.
StepFun’s docs also include deployment paths for modern inference engines like vLLM (including Step3-specific parsers and serving flags), and they also provide SGLang launch instructions in their deployment guidance.
API availability: hosted vs. self-hosted
Two different “API stories” matter here:
- Self-hosted API: because the model is open, you can stand up an internal REST endpoint (or gRPC) and treat Step3 as an internal service.
- Vendor API surface: StepFun also offers Step3 via its hosted platform API (OpenAI-compatible), for teams that want fast integration without operating GPUs.
For non-technical leaders, here is the translation:
| Question | Step3 reality | Why it matters |
|---|---|---|
| Can we automate it? | Yes (deployable plus callable) | Lets you run image and text checks at scale, not one-by-one |
| Is it API-ready? | Yes (self-host, plus StepFun hosted API) | API access is the difference between “tool” and “infrastructure” |
| Is it plug-and-play? | Not automatically | You still need orchestration, queues, logging, approvals |
Where it feels production-leaning
Step3’s release is surprisingly aligned with what “real” adoption needs:
- Apache 2.0 licensing (clean commercial path)
- MoE efficiency posture (large capability without fully paying for a dense model every call)
- Deployment guidance that assumes serving reality (including vLLM and SGLang)
- Long context that supports audit-style workflows
In other words, this is not just “we released weights.” It is “we released weights and expect you to build with them.”
What is still hype-adjacent (aka: do not bet your quarter on it)
Even with a strong release posture, multimodal automation still has sharp edges:
- Hallucinations do not disappear because it is open-source. Vision-language models can still invent details, misread small text, or overconfidently infer what is not there.
- Brand compliance is a system problem. A model can flag issues, but your workflow needs “critics,” thresholds, and escalation logic to avoid false positives and false negatives turning into chaos.
- Serving costs move from tokens to operations. If you do not have cost controls, batch jobs and agent loops will happily run up a tab.
The model is the engine. Your workflow is the vehicle. If the vehicle has no brakes, do not blame the engine.
What teams should do with this news
If you are an executive or marketing operator scanning for what is actually actionable, Step3 is worth attention for one reason: it makes multimodal capability ownable. You can run it privately, integrate it into your systems, and avoid being trapped behind a single UI or vendor roadmap.
The most realistic near-term play is not “build an autonomous creative director.” It is:
- automate the repetitive checks (tagging, QA, basic compliance)
- route edge cases to humans with clear receipts (what failed and why)
- treat multimodal as a repeatable pipeline stage, not a chat experience
Bottom line
StepFun’s Step3 is a meaningful open-source multimodal release because it targets the boring constraints that make automation possible: cost posture, deployability, and integration readiness. With open code and weights on GitHub, distribution via Hugging Face, and Apache 2.0 licensing, Step3 has the ingredients to become a real component in content and marketing systems, especially for teams that want vision-language automation without surrendering control of data and workflows.
It will not replace taste, judgment, or governance. But it can absolutely replace a chunk of the grind. And that is the whole point of scaling creativity with intelligent machine collaboration.
Ready to Automate Your Marketing Operations?
COEY connects AI tools like n8n, Claude Cowork, and OpenClaw into production-grade marketing workflows. We help brands and agencies move from manual processes to intelligent automation. Check out our automation platform, browse our AI Studio, or start a conversation.



