
Microsoft’s New Audio Models Make Voice Automation More Real
Microsoft’s New Audio Models Make Voice Automation More Real
April 5, 2026
Microsoft has introduced MAI-Voice-1 and MAI-Transcribe-1, two in-house audio models now in public preview through Microsoft Foundry, with MAI-Transcribe-1 also available through Azure Speech. The bigger story is not just better voice AI. It is that Microsoft is turning speech into a more practical automation layer for enterprise teams that actually need to ship.
That matters because voice AI has spent plenty of time in demo-land: slick samples, dramatic narration, one surprisingly emotional synthetic sentence, cue applause. But the real question for operators, marketers, and content teams is more boring and much more important: can this plug into production without becoming yet another fragile workflow gremlin? Microsoft’s answer looks increasingly like yes.
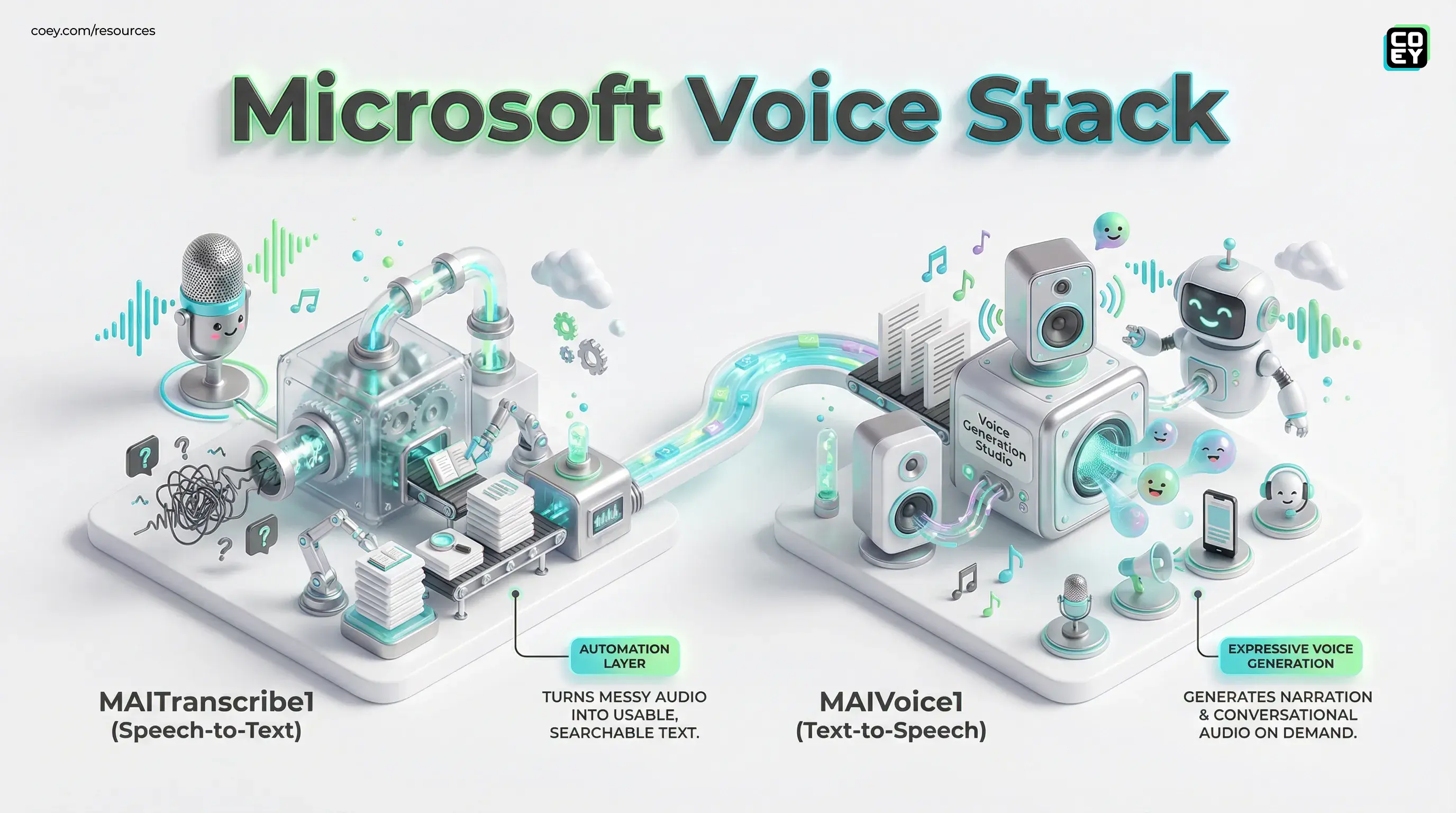
What Microsoft actually launched
MAI-Voice-1 is Microsoft’s new text-to-speech model for generating natural, expressive audio. MAI-Transcribe-1 is its speech-to-text model for turning spoken audio into usable text across 25 supported languages. Both are part of Microsoft’s broader push to own more of its AI stack instead of simply renting someone else’s magic trick.
According to Microsoft’s own materials, MAI-Transcribe-1 is positioned as a state-of-the-art transcription model built for noisy, real-world audio, not just pristine studio clips where everyone speaks like a podcast host with a condenser mic and excellent hydration. MAI-Voice-1, meanwhile, is built for fast, expressive voice generation, and Microsoft says it supports HD voices, voice prompting, and controlled emotional expression. Personal Voice style custom voice features are available with approval and responsible AI controls.
The key shift: Microsoft is no longer just offering audio AI as a feature. It is packaging it as infrastructure.
That distinction matters. Features are nice. Infrastructure gets budget.
Why this is bigger than voice UX
Most coverage around new voice models leans into realism, emotion, and whether the generated speech sounds less robotic than the last release. Fine. Useful. But for businesses, the more consequential story is workflow readiness.
These models are landing through Microsoft Foundry, and MAI-Transcribe-1 is also documented for use in Azure Speech. That means they are not trapped in a consumer app. They are exposed through developer surfaces that can feed larger systems: transcription pipelines, content ops, call analytics, localization workflows, AI agents, meeting summaries, customer service automation, and media production.
In plain English: this is voice AI that can be wired into the stack, not just played with in a shiny interface.
| Model | What it does | Automation value |
|---|---|---|
| MAI-Transcribe-1 | Speech-to-text across 25 supported languages | Turns calls, meetings, interviews, and uploads into searchable, reusable text |
| MAI-Voice-1 | Text-to-speech with expressive output | Generates narration, branded voiceovers, and conversational audio on demand |
Transcription is the immediate workhorse
Of the two launches, MAI-Transcribe-1 may be the less flashy headline and the more immediately useful one. Microsoft says it improves speed and cost efficiency while maintaining high transcription accuracy, including on messy audio. That is exactly where real-world value lives.
Transcription is often the first step in scaling human creativity with machines because text is easier to summarize, tag, search, transform, analyze, and route. Once audio becomes text, it can move through the rest of your AI stack. That means one spoken asset can become ten downstream outputs: meeting notes, CRM summaries, content drafts, social clips, training docs, support insights, compliance logs, and multilingual repurposing.
This is where nontechnical teams should pay attention. If your company already records conversations, webinars, interviews, demos, or support calls, MAI-Transcribe-1 is not just a convenience tool. It is an ingestion layer for automation.
And yes, it appears commercially viable too. Microsoft lists MAI-Transcribe-1 at $0.36 per audio hour, and the model is available in Foundry public preview. Microsoft’s documentation also notes that the current release is focused on batch transcription, while features such as real-time transcription, speaker diarization, and context biasing are planned for future updates.
Voice generation is useful, with caveats
MAI-Voice-1 is the model that will get more attention because generated speech is visceral. Everyone instantly has an opinion. “Wow, that sounds real.” “Absolutely cursed.” “This would save us six hours a week.” All valid.
Microsoft says the model can generate up to 60 seconds of audio in about one second on a single GPU, which is a meaningful performance signal if it holds up in production. Speed matters because the best use cases for voice generation are not one-off novelty clips. They are high-volume jobs: product explainers, ad variations, internal training audio, voice agents, app narration, localization, and dynamic content systems.
The custom voice angle is especially interesting. Microsoft is supporting consent-based voice creation with approval-gated controls. That is good. It should be the minimum, frankly. In a market still trying to prove it can behave like an adult around synthetic media, guardrails are not optional.
Still, voice cloning is where teams need to avoid main-character syndrome. Just because you can clone a voice does not mean you should. The practical winner here is not celebrity-ish mimicry. It is consistent branded narration, approved executive voice use, accessible content, and scalable multilingual customer experiences.
Can you automate it today?
Mostly yes, especially if you already live inside Microsoft’s cloud. These models are available through Foundry surfaces, and MAI-Transcribe-1 is also exposed through Azure Speech tooling. That means they can be called through APIs and connected to event-driven workflows, internal tools, and orchestration layers.
For technical teams, that opens the usual doors: REST calls, batch jobs, triggered pipelines, app integrations, and voice-enabled agents. For nontechnical teams, the real translation is simpler: if your systems can already trigger actions when a file is uploaded, a meeting ends, or a form is submitted, these models can likely become part of that chain.
| Workflow | Now or later | What it enables |
|---|---|---|
| Batch transcription via API | Now | Auto-process calls, interviews, webinars, and archives |
| TTS for branded narration | Now | Create voiceovers for product, campaign, and support content |
| Streaming and richer speaker features | Later | More advanced live agents and conversation analytics |
That last row matters. Not every desirable audio feature is fully here yet. Microsoft’s current documentation suggests some advanced capabilities, including real-time transcription and speaker diarization for MAI-Transcribe-1, are still on the roadmap rather than broadly available today. So this is not the moment to pretend every enterprise voice workflow is solved. It is the moment to say Microsoft has moved the ball from “interesting” to “deployable in many cases.”
What this means for creators and marketers
For marketing teams, the appeal is speed and scale. Transcribe customer interviews, mine the best quotes, turn transcripts into briefs, and spin up narrated variants for different channels. For content teams, it means one recorded asset can become many deliverables with much less manual drag. For customer experience teams, it means faster summaries, searchable calls, and more natural voice interfaces.
For executives, the takeaway is even simpler: this is the kind of AI upgrade that reduces labor around content transformation without removing human judgment from the loop. That is exactly where AI tends to earn its keep.
If this sounds familiar, it fits a broader trend we have been tracking on the COEY blog: the market is shifting from isolated model launches to workflow-native AI infrastructure. We saw a similar pattern in our coverage of Mistral’s Voxtral Transcribe 2, where the real story was not raw capability but whether teams could reliably operationalize it.
Microsoft is making a platform play
This launch is not just about catching up in audio. It is part of Microsoft’s larger strategy to own more of the multimodal stack across text, image, voice, and agents. That should get everyone’s attention because Microsoft has distribution, enterprise trust, and the admin-friendly cloud plumbing needed to turn “AI feature” into “default workflow layer.”
That does not guarantee dominance. Closed ecosystems always come with tradeoffs, and buyers should still ask the obvious questions around portability, governance, pricing drift, and how much of the good stuff remains gated behind previews or approval flows.
But on readiness, these audio models look materially more practical than the average launch hype cycle. Not magic. Not sci-fi. Not “replace your whole team by Tuesday.” Just useful infrastructure that can help teams move faster.
The bottom line: MAI-Voice-1 and MAI-Transcribe-1 are not merely new audio models. They are a sign that Microsoft wants voice to become a standard automation primitive inside enterprise creative and operational systems. For teams building human-plus-machine workflows, that is the part worth watching.
Scale Your Content With AI Agents That Deliver
COEY helps brands and agencies automate content creation, marketing ops, and campaign execution using n8n, Claude Cowork, OpenClaw, and custom integrations. See how our agentic automation works across every marketing channel, or request a proposal.
Related: How to Build an AI Content System – The Full Playbook for Brands and Agencies.
For marketing leaders ready to turn AI strategy into production workflows, explore the Executive AI Accelerator.



