
AI MODEL
Kling 01 T2I
Kling O1 text to image is the still image mode of the larger Kling O1 multimodal system from Kuaishou. It takes natural language prompts and optional reference images and produces high quality static visuals rather than video. The model is built on a unified multimodal visual language architecture that combines language understanding with visual reasoning, which helps it follow detailed instructions, interpret multiple references, and generate coherent images with strong structure. It supports multi reference input with up to ten images and can perform precise edits guided by text or simple sketches. Output is delivered at 1K or 2K resolution with clean subject rendering, which makes it a good match for multi reference branding and character consistent creative work.

Compare outputs for Closeup Portrait
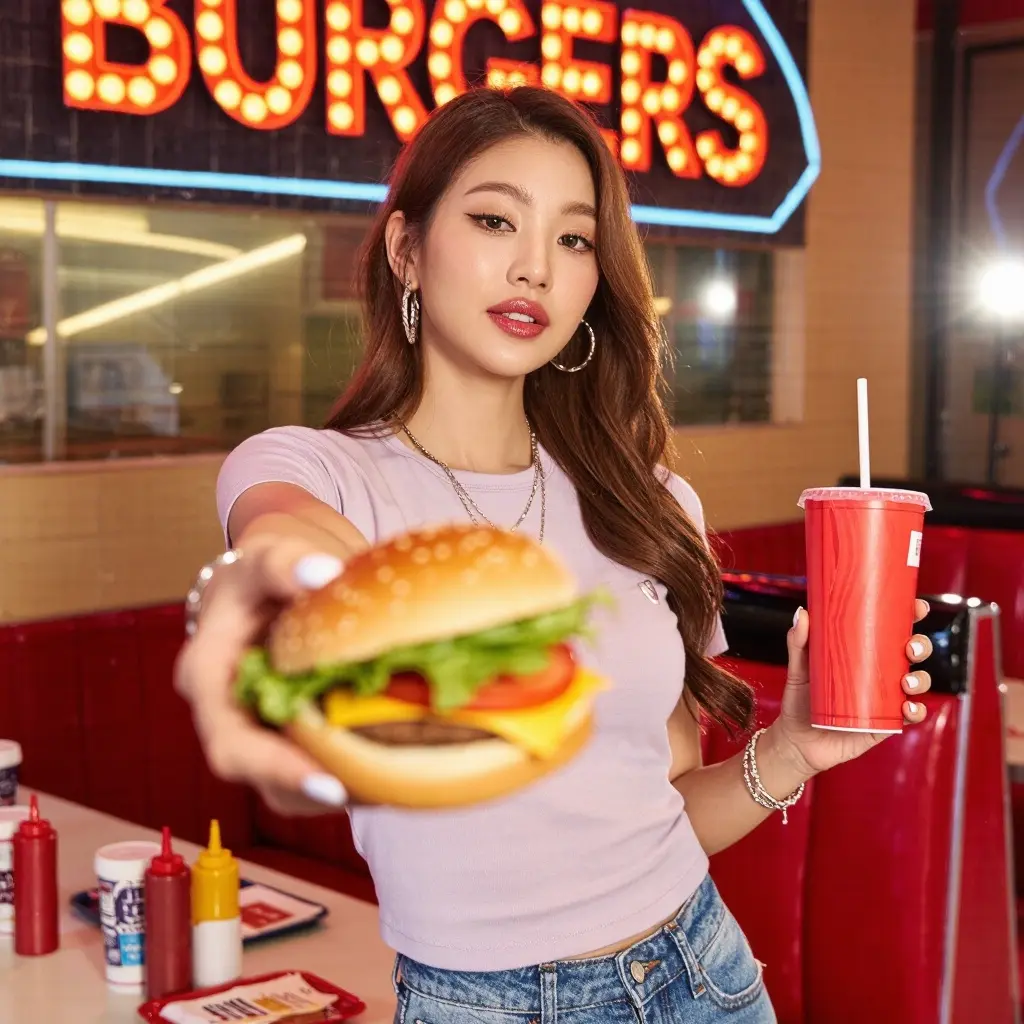
Compare outputs for Burger Time

Compare outputs for Gather & Sip

Compare outputs for Suns Out

Compare outputs for Stronger Every Day

Compare outputs for Bum Rush

Compare outputs for Marquess

Compare outputs for Nova Repair Serum

Compare outputs for Mirror Selfie

Compare outputs for Reach The Summit
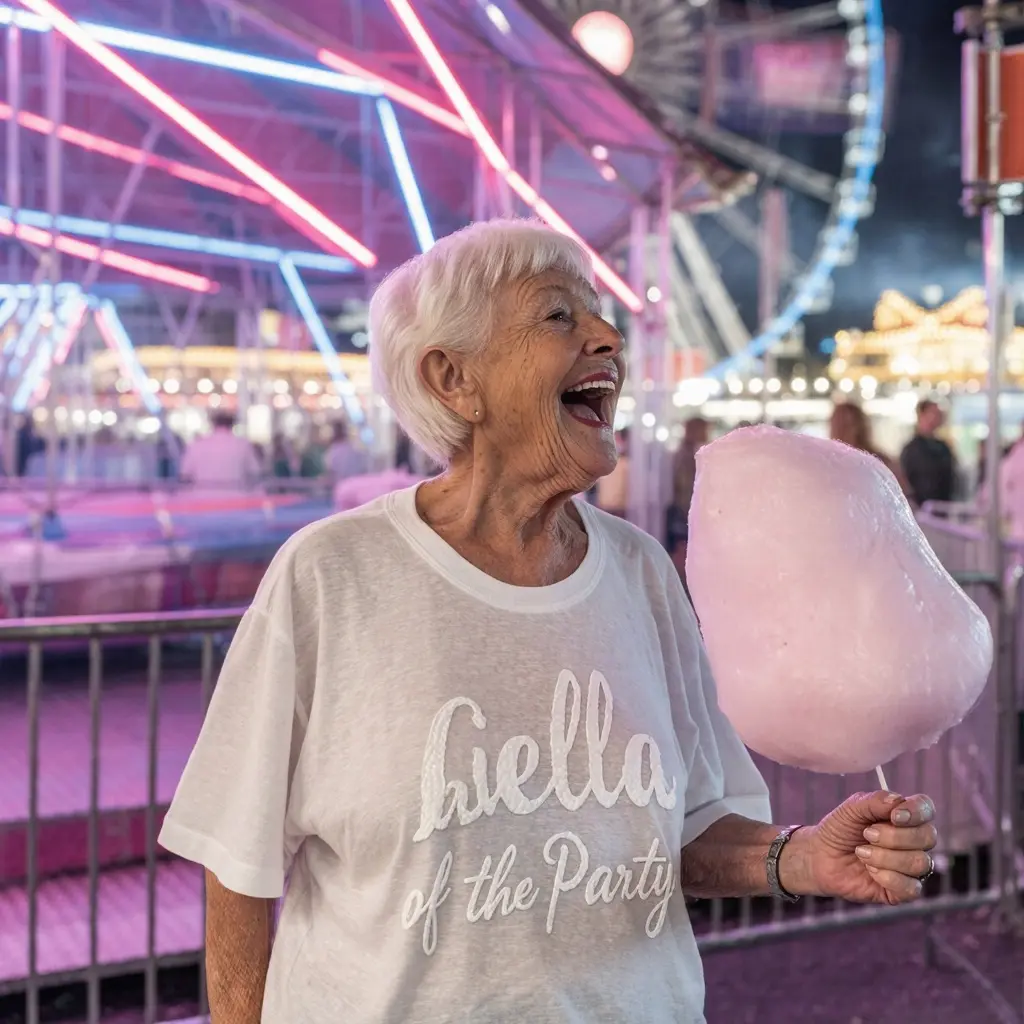
Compare outputs for Life of the Party