
AI MODEL
GPT Image 1.5 T2I
GPT Image 1.5 text to image is OpenAI's multimodal image generation model, built to turn natural language prompts into high fidelity visuals with strong semantic accuracy. It follows detailed instructions closely, handles complex multi object scenes, renders readable text inside images, and maintains consistent object relationships across compositions. The model benefits from tight integration between language understanding and visual generation, which improves prompt adherence and reduces common issues like misplaced elements or incoherent layouts. GPT Image 1.5 T2I is optimized for illustrative, informational, and design oriented use cases where correctness, clarity, and controllability matter as much as raw visual quality. It is priced about 20 percent lower than GPT Image 1 for both inputs and outputs, making it a practical default for iterative workflows.

Compare outputs for Closeup Portrait

Compare outputs for Fashion Shoot

Compare outputs for Survive The Grind

Compare outputs for How Wind Turbines Work

Compare outputs for Bum Rush

Compare outputs for Reach The Summit

Compare outputs for Nova Repair Serum

Compare outputs for Stronger Every Day

Compare outputs for Suns Out

Compare outputs for Gather & Sip

Compare outputs for Burger Time
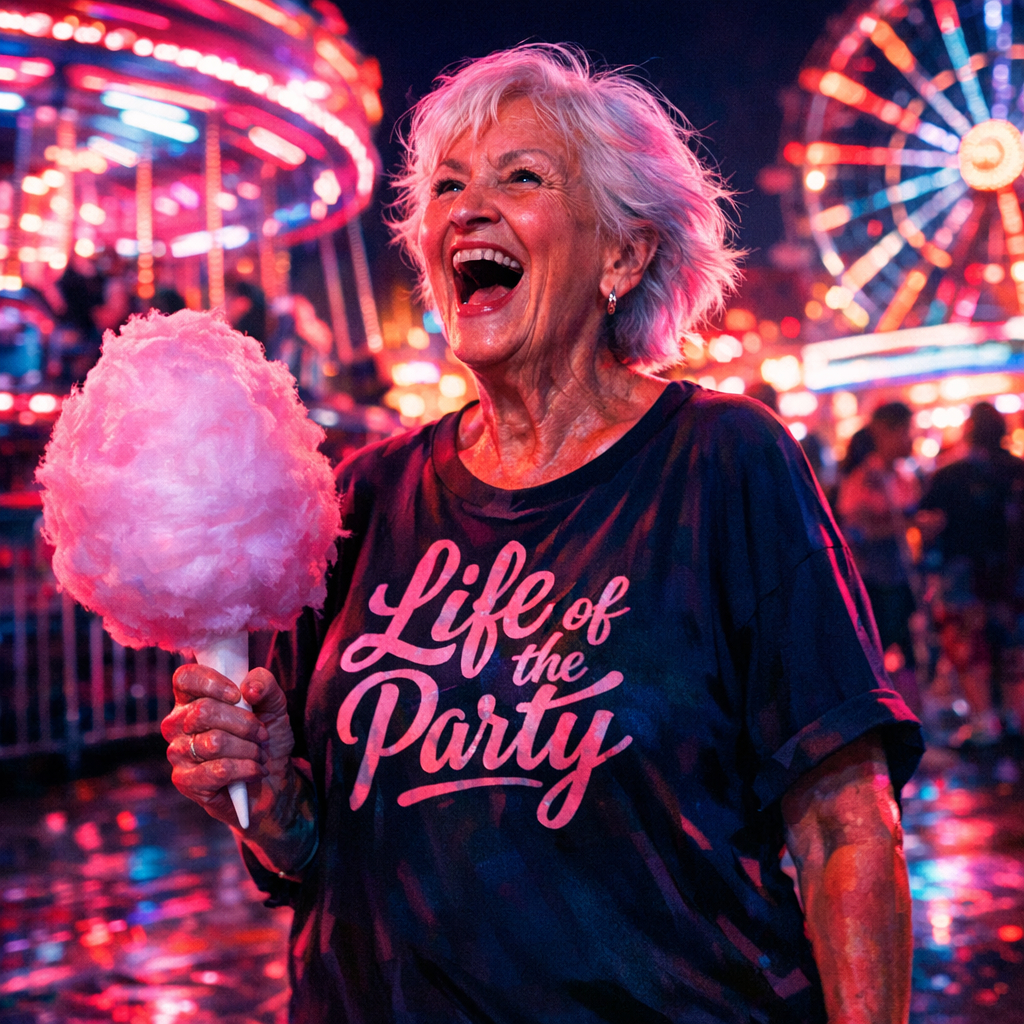
Compare outputs for Life of the Party

Compare outputs for Mirror Selfie

Compare outputs for COEY River Rocks

Compare outputs for Athletic Man

Compare outputs for Editorial Influencer Shoot

Compare outputs for Virtual Influencer