
Moonshot AI’s Kimi K2.5 Drops “Agent Swarm” Parallelism and It’s Built for Automation
Moonshot AI’s Kimi K2.5 Drops “Agent Swarm” Parallelism and It’s Built for Automation
January 29, 2026
Moonshot AI just shipped Kimi K2.5, and yes, it’s another “frontier” model announcement, but the interesting part isn’t the parameter flex. It’s the fact that K2.5 is explicitly designed to run multiple sub-agents in parallel (Moonshot calls it “Agent Swarm”) and expose that capability through an API you can actually wire into a real content pipeline. If you’ve been trying to scale creative output without turning your team into prompt babysitters, this release is aimed directly at your pain.
Start here: the official surfaces are the Moonshot AI platform and the Kimi API docs. And if you want the open-weight angle (or at least open-weight-adjacent), the model page on Hugging Face is where the technical crowd will congregate.
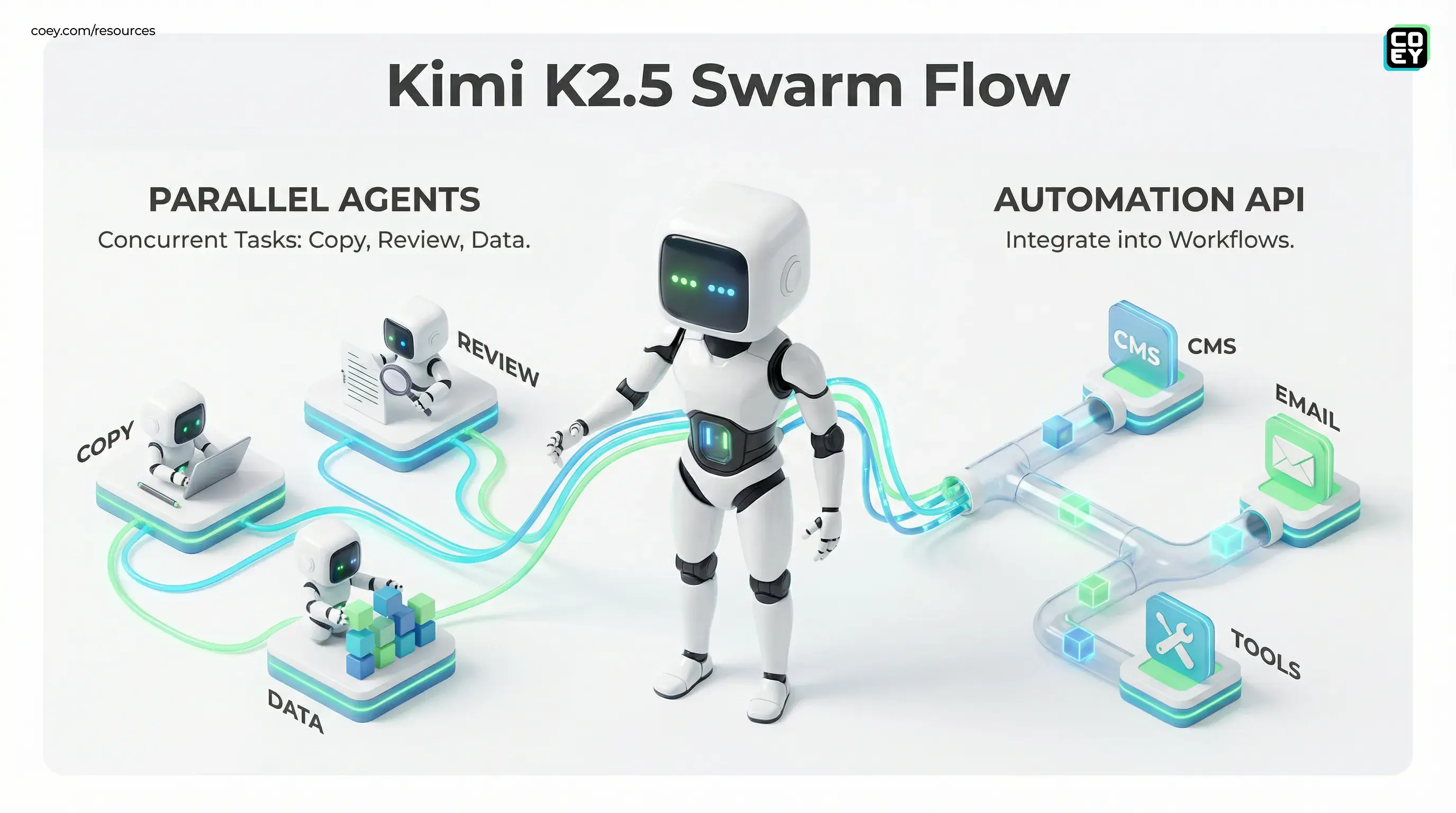
What shipped (in plain English)
Kimi K2.5 is a multimodal model (text + vision, with video understanding also supported) that Moonshot positions as “agentic by default.” Translation: it’s not just built to answer questions. It’s built to do things: call tools, coordinate steps, and complete multi-stage work without you manually chaining ten prompts together like it’s 2023.
Three headline claims matter for creative ops teams:
- Parallel sub-agents (“Agent Swarm”): break a job into concurrent subtasks instead of running everything sequentially (Agent Swarm is described as a beta feature).
- Huge context: a ~256k-token context window (commonly cited as 256,000 tokens; some materials reference 262,144 as the technical maximum), which is “entire campaign brief + brand bible + product docs + past emails” territory.
- Tool-first posture: designed for tool calling and orchestration, not just chat UX.
Why this is different: most “agent” launches are just wrappers around a model. K2.5 is trying to bake concurrency into the model’s execution style. That’s a real lever for throughput, if it holds up outside of demos.
Parallel agents: the throughput play
Marketers don’t lose time because they can’t generate copy. They lose time because everything is multi-step: draft, validate, format, version, tag, resize, localize, push to tools, QA links, rerun, repeat. Sequential agent chains turn that into a latency tax.
Moonshot’s bet with Agent Swarm is simple: if one “job” needs multiple workstreams, don’t serialize them.
In real campaign terms, parallel sub-agents can mean:
- One agent generates copy variants while another extracts key claims from your docs and another prepares structured metadata for CMS upload.
- One agent reviews existing creative for compliance issues while another creates localized versions (and ideally doesn’t “localize” your brand voice into corporate oatmeal).
- One agent preps ad copy while another drafts landing page sections and another assembles UTM-ready links.
This matters because the “agentic future” isn’t one super-assistant. It’s a coordinated team of narrow workers. K2.5 is basically saying: “Cool, we’ll be the manager and the team.”
API reality: can you automate this?
Here’s the practical check: K2.5 is not just an app feature. Moonshot offers developer access via the Moonshot platform and documents an OpenAI-style API surface in the Kimi docs. For automation teams, that’s the unlock, because anything with a predictable HTTP API can be dropped into:
- n8n / Make / Zapier (via HTTP modules)
- custom middleware (Node/Python) that brokers prompts, tools, and logs
- agent frameworks that already assume chat-completions-style endpoints
“OpenAI-compatible” is not a buzzword here. It’s a migration path. If your stack already knows how to call OpenAI-style endpoints, you can test K2.5 without re-architecting everything.
| Question | What K2.5 suggests | What it means operationally |
|---|---|---|
| Is there an API? | Yes, documented in Kimi API docs | You can run it inside automations, not just chats |
| Can it call tools? | Designed for tool calling + orchestration | Less “copy output,” more “workflow engine” |
| Is it production-ready? | Depends on your tolerance for eval + guardrails | Plan for QA layers, logs, and safe retries |
Context window: why 256k is not just trivia
Long context has become the new “my model can benchpress your model,” but for execs and operators it’s only valuable if it removes process friction.
K2.5’s long context is most useful when you’re doing high-cohesion work where the cost of losing context is rework:
- Campaign packs: one brief → landing page + emails + social + ad variants that don’t contradict each other.
- Brand consistency: keeping tone stable across 40 assets without duct-taping a “voice prompt” onto every single call.
- Content ops memory: using prior approved copy + disclaimers + product truth in the same run.
The catch: long context does not equal long attention. You still need structure (schemas, checkers, critics) or you’ll get beautifully-written inconsistencies at scale.
Benchmarks vs. “will it ship?”
Moonshot is positioning K2.5 as competitive on multimodal understanding and coding tasks, and the open-weight chatter on Hugging Face will keep that conversation loud. But marketing teams don’t win on MMMU scores. They win on:
- first-pass validity (how often the output is usable without edits)
- throughput (assets/hour with guardrails on)
- integration friction (how fast it plugs into CMS/ESP/DAM workflows)
- cost predictability (no “agent loop burned $900 overnight” surprises)
So treat benchmarks like a résumé. You still need an interview.
Where this is actually ready today
K2.5 looks most “real” in environments where you already have automation muscle and just need a stronger orchestration brain.
- Agencies: batch creation + localization + packaging deliverables (especially if you already run standardized templates).
- Lifecycle teams: variant generation plus structured formatting for ESP ingestion.
- Content ops: tagging, summaries, metadata enrichment, and multi-asset assembly where tool calling matters more than vibes.
- Product marketing: turning dense docs into consistent, multi-channel assets without context drop-offs.
Less ready (or at least: more risk) for fully autonomous publishing. Parallel sub-agents can multiply mistakes just as easily as they multiply output. If you don’t have gates, you’re basically giving an intern squad API keys to your brand.
The boring parts that decide success
This is the stuff that determines whether K2.5 becomes a real workflow engine or a cool demo your team forgets in two weeks:
- Structured outputs: insist on JSON schemas for campaign assets, not freeform paragraphs.
- Critic layers: brand tone checks, claims checks, link hygiene, accessibility, and “do we have sources?” validation.
- Budgets + retries: parallelism without caps is how you get surprise invoices and surprise apologies.
- Receipts: logs for what ran, what tools were called, what changed, and who approved what.
If you want the broader systems framing for this (because the model is only one part of the machine), COEY has already been mapping the pattern: Your Stack Needs an AI Control Plane.
Bottom line
Kimi K2.5 is a clear signal that the model race is shifting from “who writes the best paragraph” to “who coordinates the most work per minute.” Parallel sub-agents plus an automation-friendly API is a credible move toward machine collaboration that actually scales creative output, not just brainstorms it.
Just don’t confuse “swarm” with “autopilot.” The teams that win with this will be the ones who treat K2.5 like a high-throughput coworker: scoped permissions, structured deliverables, validation gates, and a human still owning taste and accountability. That’s the whole human + machine deal, and it’s finally starting to look operational, not theoretical.



