
Alibaba’s Qwen-Image-Agent Tackles the Prompt Gap
Alibaba’s Qwen-Image-Agent Tackles the Prompt Gap
June 29, 2026
Alibaba’s Qwen team has introduced Qwen-Image-Agent, an agentic framework for text-to-image generation that tries to solve one of the most annoying problems in AI visuals: users rarely provide enough context, and models often respond by confidently guessing. The new system reframes image generation as a multi-step reasoning workflow instead of a one-shot prompt-to-picture trick. For marketers, creative teams, and automation-minded operators, that distinction matters. This is not just “make prettier pixels.” It is a move toward image systems that can plan, search, remember, evaluate, and revise before producing an asset.
That is a big deal because the creative world has already learned the hard way that prompt boxes are not production pipelines. A normal image model can make a stunning product shot from a perfect prompt. Wonderful. Now ask it to create a campaign visual using vague brand direction, current product context, layout constraints, and a follow-up revision from a creative director who says “make it feel more premium but less try-hard.” Suddenly the magic starts sweating.
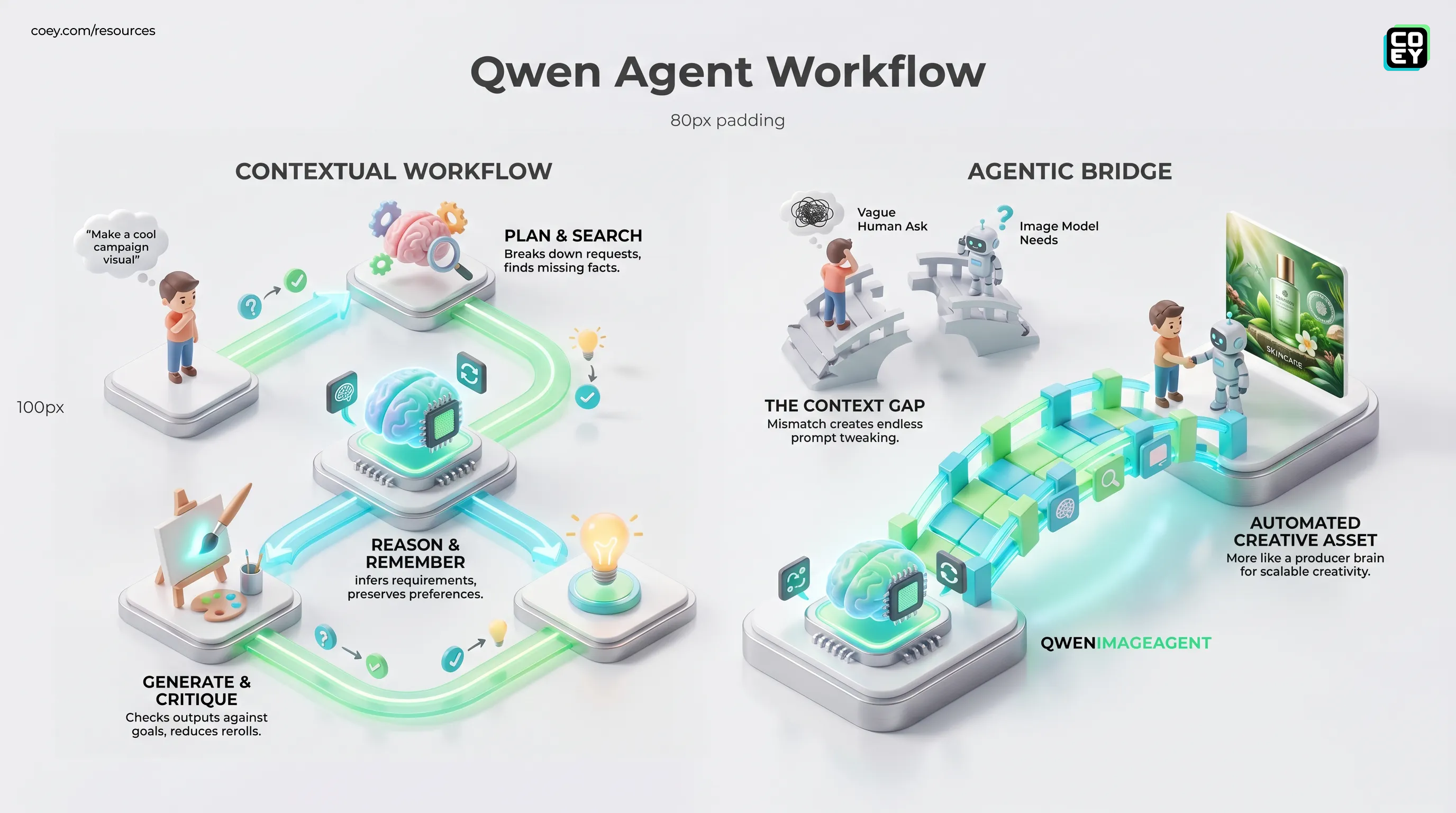
The useful shift in Qwen-Image-Agent is not that it generates images. It is that it treats image generation like a workflow with context gathering, planning, feedback, and memory.
What Alibaba Built
Qwen-Image-Agent is described in the research paper “Qwen-Image-Agent: Bridging the Context Gap in Real-World Image Generation” as a training-free agentic framework for real-world image creation. “Training-free” means the framework is not necessarily a brand-new image model trained from scratch. Instead, it sits around an image model and improves the process that leads to generation.
The core idea is simple: most image prompts are incomplete. A user might ask for “a launch graphic for our new skincare line,” but the model still needs to know visual style, product appearance, audience, channel format, seasonal context, brand colors, typography expectations, and what “launch” even means in this scenario. Traditional models either require the human to specify everything or they fill in the blanks with generic internet soup.
Qwen-Image-Agent tries to close that gap by building what the authors call generation context. It uses planning to identify what is missing, reasoning to infer implicit requirements, search to retrieve outside information, memory to preserve preferences across turns, and feedback to check whether generated outputs match the task.
| Component | Role | Creative impact |
|---|---|---|
| Planning | Breaks down the request | Turns vague asks into structured image tasks |
| Search | Finds missing context | Adds facts, references, or current visual cues |
| Feedback | Checks outputs against goals | Reduces rerolls and off-brief assets |
Why Context Is The Problem
Text-to-image models have improved dramatically, but they still have a very human flaw: they perform best when someone tells them exactly what to do. Unfortunately, that is not how most real creative work begins.
Creative briefs are messy. Stakeholders are vague. Brand guidelines live in PDFs nobody has opened since the rebrand. Product details change. And the phrase “make it pop” continues to haunt civilization like a cursed relic. In that environment, a model that simply renders the first prompt is useful, but limited.
Alibaba’s framing of the “context gap” is accurate. The gap is the mismatch between what a human casually asks for and what an image model actually needs to generate something useful. That gap creates the reroll tax: endless prompt tweaking, visual misalignment, and outputs that look cool but fail the job.
For marketers, this matters because production quality is not only about aesthetics. It is about whether an asset is on-brand, channel-ready, factually aligned, legally safe, and consistent across campaign variants. A gorgeous image that forgets the product detail, mangles the logo, or invents a visual claim is not an asset. It is a meeting invitation.
How The Agent Works
The framework uses a staged process rather than a single generation call. First, it performs context-aware planning. That planning happens across multiple levels: identifying missing information, rewriting the prompt into a more complete generation instruction, and managing multi-turn or multi-image workflows so the system does not drift.
Then it grounds the context through reasoning, search, memory, and feedback. In plain English, the agent asks: What does the user probably mean? What facts or references are needed? What has this user already said in the conversation or prior task? Did the generated image actually satisfy the checklist?
This is where the system becomes more interesting than a fancier prompt enhancer. Prompt enhancers rewrite what you say. Agentic systems can decide what information is missing, where to get it, and how to evaluate the result. That does not make them magically correct. It does make them much closer to the way a human creative team works: brief, clarify, research, draft, review, revise.
Qwen-Image-Agent is basically trying to give image generation a producer brain. Not the full creative director. More like the organized person in the room asking, “Do we actually have the product reference before we make 40 assets?”
IA-Bench Raises The Bar
Alongside the framework, Alibaba introduces IA-Bench, short for Image Agent Bench. This benchmark is designed to evaluate image agents on more realistic capabilities than “did the picture look nice?” The benchmark covers planning, reasoning, search, and memory across 17 real-world task types, 730 test instances, and 1,801 fine-grained checklist items.
That is important because image generation benchmarks often reward surface quality while under-testing operational usefulness. A model can produce a beautiful cyberpunk bakery and still fail at creating a coherent retail display with correct products, layout, signage, and campaign constraints.
IA-Bench uses checklist-based evaluation, which is much closer to how teams actually review creative work. Did the asset include the required elements? Did it follow the layout instruction? Did it preserve the preference from earlier turns? Did it use the retrieved context correctly?
The paper reports that Qwen-Image-Agent outperforms strong direct-generation baselines and other agentic approaches across IA-Bench, as well as additional benchmarks including MindBench and WISE-Verified. The reported IA-Bench headline number is an IA-score of 45.4, compared with 17.4 for direct generation in the paper’s baseline comparison, and the authors also report a 90.2% result on WISE-Verified. That is promising, but it is still research evaluation. Benchmarks are useful signals, not procurement decisions. Nobody should replace their production workflow because a chart looked emotionally compelling.
Automation Potential
This is where the story gets practical. Qwen-Image-Agent has real automation potential, but not in the “click one button and your brand studio becomes sentient” way. Let’s keep the confetti cannon holstered.
The agent structure maps naturally to automated creative production: input a campaign request, gather references, generate candidate images, evaluate them against a checklist, and route the strongest outputs to human review. That could support ecommerce imagery, paid social variants, campaign concepts, editorial visuals, localization, and internal creative QA.
For non-technical readers, the API question is the key one. At the framework level, there does not appear to be a broadly packaged, enterprise-ready hosted API specifically for Qwen-Image-Agent. The work is currently best understood as a research framework connected to Alibaba’s broader Qwen image ecosystem. Qwen image generation and editing models are available through Alibaba developer channels, including Qwen Cloud image generation documentation, DashScope or Model Studio, ModelScope, Hugging Face, and GitHub depending on the model and version. The newest Qwen image stack also includes Qwen-Image-2.0 and related 2026 releases, while a dedicated public endpoint for the full agentic Qwen-Image-Agent workflow has not been clearly confirmed. That means technical teams can experiment, wrap components, and potentially deploy custom endpoints, but should not assume there is a turnkey Qwen-Image-Agent API yet.
| Question | Answer now | Meaning |
|---|---|---|
| Can teams test it? | Yes, with technical setup | Best for research and prototyping |
| Is there a turnkey API? | Not clearly confirmed | Not plug-and-play for most teams |
| Can it be automated? | Potentially, if deployed | Requires engineering and orchestration |
That matters. A framework can be brilliant and still not ready for a marketing ops team using Make, Zapier, Airtable, or a CMS without engineering support. API availability is the line between “cool research” and “repeatable business system.” Qwen-Image-Agent looks architecturally automation-friendly, but not yet packaged as a low-friction enterprise tool.
Where It Fits For Teams
The clearest near-term fit is advanced creative operations: teams that already have developers, model infrastructure, or custom AI pipelines. For those groups, the framework points to a better way to produce images at scale. Instead of sending raw prompts to a model and hoping for the best, teams can design a pipeline where the AI gathers context, checks requirements, and iterates before a human reviews the output.
That kind of workflow could reduce time spent on prompt babysitting. It could also improve consistency across asset batches. Imagine feeding a system a product feed, brand rules, seasonal campaign direction, and a list of formats. The agent could generate more complete prompts, retrieve missing references, produce variants, evaluate them against a checklist, and send only viable options into review. The human still makes the call. The machine removes a lot of the grind.
This is especially relevant as image models become more operational. COEY covered a similar production shift in Microsoft’s MAI-Image-2 rollout, where the big story was not just image quality, but API access and workflow readiness. As of late June 2026, Microsoft’s comparable image line has moved to MAI-Image-2.5 and MAI-Image-2.5-Flash in Microsoft Foundry preview, with text-to-image and image editing support. Qwen-Image-Agent is pushing from the research side toward the same destination: image generation that behaves less like a toy and more like a creative system.
There is also a useful contrast with COEY’s coverage of Midjourney V8 Alpha. Midjourney keeps improving output quality and speed, but the API-first story remains a limitation for teams that want deep automation. Qwen-Image-Agent raises a related but different question: what if the bottleneck is not only model access, but also the missing context layer before generation ever starts?
The Readiness Reality
Qwen-Image-Agent is meaningful, but it is not a fully packaged creative platform for mainstream teams yet. The strongest signal is conceptual and architectural: image generation is becoming agentic. The weaker signal is product readiness: availability, hosting, governance, cost controls, and enterprise integration still need to be proven.
There are also practical risks. Search-connected generation needs source control and rights awareness. Memory needs privacy boundaries. Feedback loops need reliable evaluation criteria. And generated assets still need brand, legal, and human taste review. Otherwise, automation just gives you wrong outputs faster, which is less “future of creativity” and more “spreadsheet goblin with a render button.”
The bottom line: Alibaba’s Qwen-Image-Agent is a strong signal that AI image generation is moving beyond one-shot prompting toward workflow-aware collaboration. It can plan, reason, search, remember, and critique in ways that better resemble real creative production. That makes it exciting for teams trying to scale human creativity with machine support. But the current readiness level looks closer to advanced prototype than plug-and-play enterprise tool.
For executives and marketers, the takeaway is simple: watch the agent layer. The future advantage will not belong to teams that generate the prettiest single image. It will belong to teams that build repeatable systems where humans define intent and taste, while machines handle context, variation, checking, and throughput. Qwen-Image-Agent is not the whole system yet. But it is absolutely pointing in the right direction.



