
Kokoro-82M Makes Local AI Voice Practical
Kokoro-82M Makes Local AI Voice Practical
July 3, 2026
Kokoro-82M is giving creators and marketing teams a very specific kind of AI gift: text-to-speech that is small, open-weight, fast, and realistic enough to matter outside the demo dungeon. The open-weight model, released under Apache 2.0, has become one of the more practical options for teams that want synthetic narration without sending every script through a cloud API meter. In a market crowded with glossy voice platforms promising “studio-quality human emotion” and occasionally delivering “customer service hold music with feelings,” Kokoro-82M stands out because it is less about theatrical hype and more about workflow gravity.
That matters. For years, AI voice has lived in two worlds: beautiful proprietary cloud tools with polished interfaces and recurring usage costs, or open-source projects that were powerful but annoying to run, tune, or automate. Kokoro-82M lands in the more useful middle. It is not the most cinematic voice system on earth. It is not a magic celebrity voice clone button. But it is small enough to deploy locally, permissive enough for commercial experimentation, and flexible enough to become infrastructure rather than just another tab in the browser graveyard.
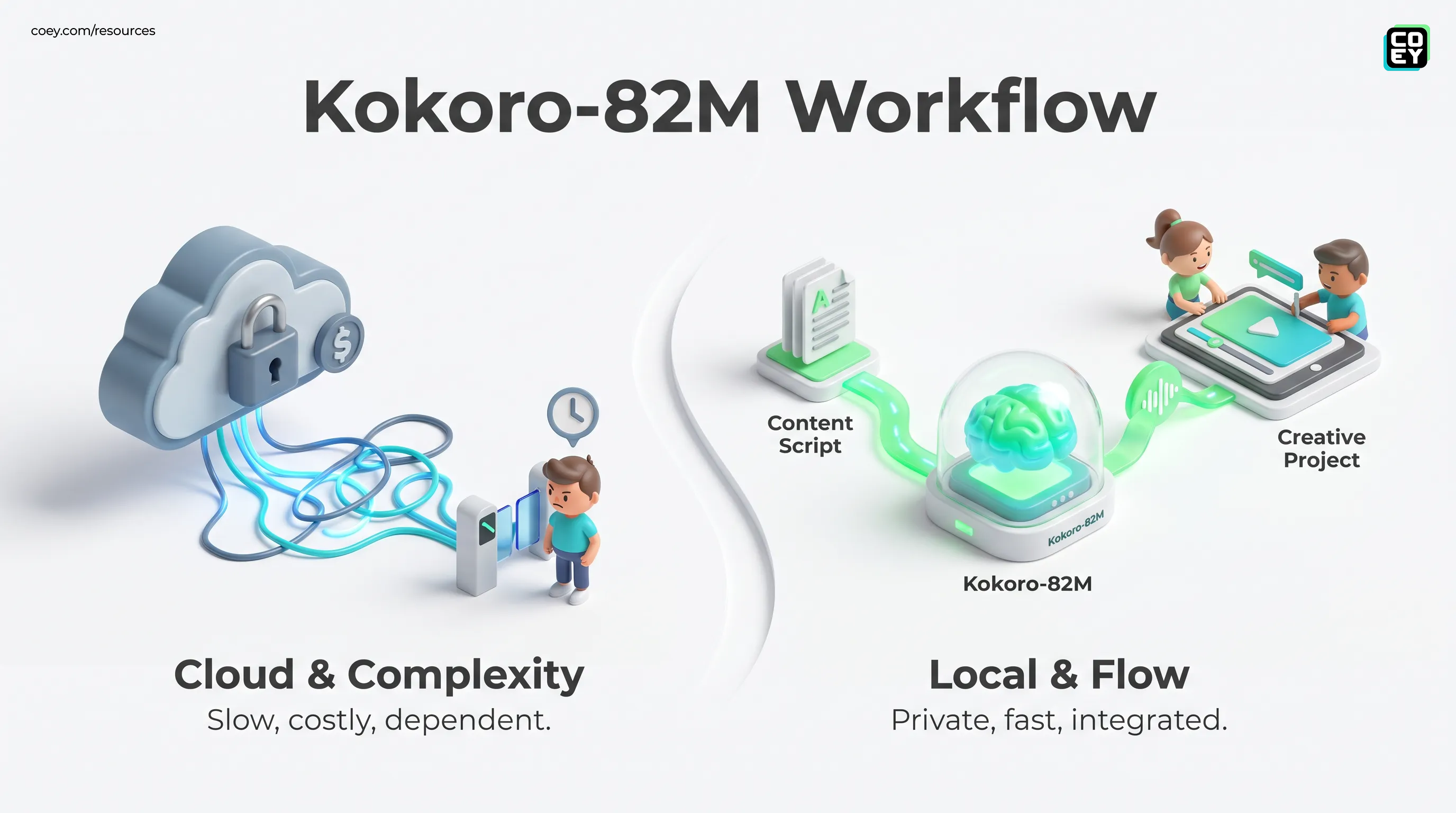
The headline is not AI voice gets smarter. The headline is AI voice gets easier to embed into private, repeatable production systems.
A Small Model With Big Timing
Kokoro-82M is an 82 million parameter neural text-to-speech model built around a lightweight architecture that uses StyleTTS 2 as its text-to-spectrogram model and iSTFTNet as its vocoder. Translation for the non-model-card crowd: it turns written text into spoken audio without needing a hulking GPU cluster or a vendor-hosted service for every single render.
The size is the story. At 82M parameters, Kokoro is tiny compared with the monster models currently stomping around AI land like Godzilla with a SaaS pricing page. That smaller footprint makes it easier to run on local machines, private servers, and edge devices. For content teams, this changes the shape of production. Instead of paying per character just to preview a script, teams can generate rough narration locally, revise copy, regenerate instantly, and only move to a premium voice provider when a project truly requires that final layer of polish.
Its current v1.0 model card points to broad voice support, with 54 preset voices across 8 language groups. That includes American and British English voice packs, plus support for Spanish, French, Hindi, Italian, Japanese, Brazilian Portuguese, and Mandarin Chinese through the available language and voice codes. English remains the strongest use case, while other languages may carry more accent, pronunciation, or prosody artifacts. That is not a dealbreaker. It is a readiness note. Kokoro is useful for drafts, internal tools, explainer content, accessibility layers, prototype localization, and high-volume narration. It is less obviously ready to replace top-tier commercial voice talent in a brand anthem video where every syllable needs to cry in Helvetica.
What It Actually Ships
The model is available on Hugging Face, and the related Kokoro inference library gives developers a way to run it in Python-based environments. There are also ONNX builds, including community-maintained v1.0 versions designed for more portable deployment across runtimes and devices. That matters because ONNX support can make models easier to run in browsers, desktop apps, and lower-friction environments where a full Python setup is not ideal.
For executives and marketing leaders, the simple version is this: Kokoro is not just a voice generator. It is a voice component. It can sit inside a larger workflow where scripts come from a CMS, campaign database, product feed, learning platform, or support article library. The model generates audio, the workflow routes that audio into video editing, captioning, review, publishing, or localization systems. Human intent still drives the message. The machine removes the repetitive “please render this paragraph again” grind.
| Capability | What It Means | Workflow Value |
|---|---|---|
| Local inference | Runs without a cloud voice API | Privacy, speed, lower iteration cost |
| Open weights | Teams can inspect and self-host | More control over deployment |
| ONNX options | Portable model execution | Edge, browser, and app integrations |
| Preset voices | 54 built-in voices, no custom cloning required | Fast narration for repeatable content |
Automation Potential
This is where Kokoro gets interesting for COEY’s world. A manual TTS tool is nice. An automatable TTS layer is leverage.
Because Kokoro is open-weight and runnable locally, teams can wrap it in a local API, connect it to internal tooling, or trigger it inside automation platforms like n8n, Make, Airflow, or custom production systems. A marketing team could generate voiceovers automatically from approved product copy. A training department could turn new policy updates into narrated modules. A support team could create audio versions of help articles without waiting on a production queue. A creator studio could batch-generate first-pass narration for 100 short-form scripts overnight and review them in the morning with coffee and only mild existential dread.
There are hosted options too. Together AI lists Kokoro-82M as an available TTS model, which gives teams a more traditional API route if they do not want to manage infrastructure. That is important because “open source” often secretly means “congratulations, you are now DevOps.” Hosted inference can bridge the gap: easier integration, usage-based pricing, less maintenance. The tradeoff is that scripts leave your environment, which may not be acceptable for confidential launches, regulated industries, or internal communications.
This broader shift toward programmable audio is already showing up across the market. COEY has been tracking that same movement in voice infrastructure, including how OpenAI’s GPT-Realtime-2 push makes voice agents more operational. Kokoro is a different kind of tool, but the pattern is similar: voice is becoming something teams can wire into systems, not just something they generate manually in a polished interface.
Where It Fits Today
Kokoro-82M is strongest when voice is a repeatable production layer rather than a one-off masterpiece. Think scaled narration, not prestige podcasting. It is especially relevant for teams producing lots of derivative content: social explainers, onboarding videos, FAQ clips, e-learning modules, app walkthroughs, sales enablement assets, internal comms, and accessibility versions of written content.
For marketers, the immediate win is iteration. Voiceover is often weirdly slow in modern content workflows. Copy changes. Legal changes copy. Product changes legal’s changes. Suddenly a 45-second video needs a new line, and the whole pipeline gets dramatic. With a local TTS model, teams can regenerate narration instantly during draft stages, keep production moving, and reserve human voice talent or premium AI voices for final hero assets.
For product teams, local TTS enables voice experiences in environments where cloud dependency is awkward: kiosks, retail displays, internal tools, desktop apps, or field devices with inconsistent connectivity. For enterprise teams, privacy is the wedge. Sensitive scripts, unreleased product messaging, executive communications, or customer-specific materials can stay inside the organization’s systems.
The Readiness Reality
Kokoro-82M is practical, but it is not frictionless. Teams still need to evaluate voice quality, pronunciation reliability, licensing obligations, and infrastructure fit. The Apache 2.0 license is commercially friendly, but some pipelines may depend on external components such as espeak-ng, which has its own license considerations. That is not a panic button. It is a “please let legal and engineering read the labels before shipping this inside a paid product” button.
There is also a difference between “can run locally” and “production-ready at company scale.” Local experiments are easy. Reliable production requires monitoring, queue handling, audio storage, quality review, fallback providers, and version control. If the model output changes after an update, you need to know. If a pronunciation fails on a product name, someone needs a correction loop. If a campaign requires emotional nuance, you may still want human performance or a premium commercial system.
The good news is that Kokoro’s footprint makes those production questions manageable. Its ONNX community builds expand deployment options, and the broader ecosystem is already moving toward wrappers, browser demos, JavaScript integrations, and API-style services. That is usually the signal that an open model is crossing from “cool GitHub thing” into “usable building block.”
Why This Matters
Kokoro-82M reflects a bigger shift in AI tooling: the best creative systems are becoming composable. Instead of one giant platform trying to own every step, teams are assembling pipelines where different models start, enhance, or finish specific jobs. A language model drafts the script. A human sharpens the story. A TTS model generates narration. An editor reviews pacing. Automation pushes assets into review and publishing. That is human plus machine collaboration in the wild, not on a conference slide with suspicious gradients.
The strategic value is not that Kokoro replaces voice actors or studio tools. It is that it gives teams another layer of creative throughput. More drafts. Faster tests. Private narration. Lower marginal cost. Better accessibility. More room for humans to spend time on concept, taste, story, and judgment instead of production drag.
Kokoro-82M is not the final boss of AI voice. It is something more useful: a lightweight, open-weight, automatable speech layer that can actually plug into modern creative workflows. For teams trying to scale content without turning every campaign into a vendor ticket, that is a very real development.



